Thinking in Tesla GPU
How to make good use of the parallel capabilities of GPUs, how to allocate and schedule various GPU memory resources, how to migrate various CPU algorithms to GPUs for acceleration... All these issues are inseparable from an understanding of GPU architecture. Given the continuously evolving nature of GPU architectures, focusing on just one generation of architecture is like capturing only a single frame from a masterpiece, making it difficult to fully grasp its essence and mysteries.
We can consider TPC as individual subsidiaries, there are a total of 8 in this unscrupulous company, let's randomly pick one to take a look at.
Related to the number of parameters, we don't need to pay too much attention, because different architectures vary, and GPUs of the same architecture with different prices are also different (after all, Nvidia is quite skilled in their techniques). Understanding the working principle is more important. If you want to optimize for a specific GPU, you can check more specific parameter information on the official website.
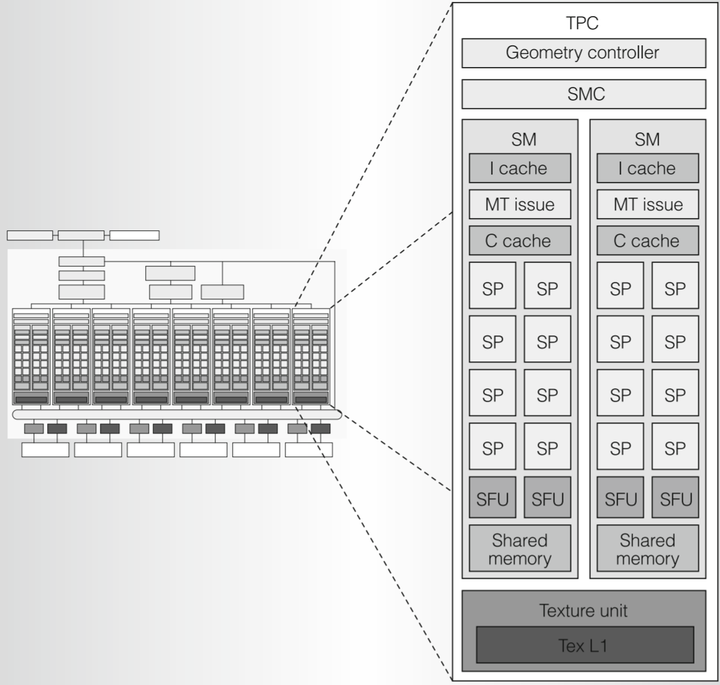
Geometry Controller: From the name, it is the big manager of the geometric stage before rasterization, responsible for the input and output of vertex attributes within the chip. Operations like the geometry shader that increase or decrease vertices and change topological structures also need its assistance. However, the computational instructions for the vertex shader and the geometry shader are still executed by the SM, and the Geometry Controller will send the final results to the Viewport/clip/setup/raster/zcull block module for rasterization and other steps, or Stream Out back to memory for programmers to manipulate. (This component was upgraded to the PolyMorph Engine in the Fermi architecture, which we will further study in the Fermi architecture chapter)
SMC (SM controller): As discussed in the previous chapter, Tesla is a unified graphics and parallel computing architecture, vertex, geometry, fragment shaders, and even parallel computing tasks unrelated to graphics (CUDA), all are computed by the same hardware SM. The SMC is responsible for dividing tasks from the headquarters into Warps (which will be detailed in the next section) and distributing them to one of the departments (SM) for processing. Besides, the SMC also coordinates the work between the SM and the shared department Texture unit to achieve access to external texture resources, while other non-texture resources in the memory and even atomic operations will deal with the outside world through the ROP. Overall, the SMC is responsible for both external resource interfacing and internal task distribution, to achieve complex but crucial load balancing, truly a senior executive of the subsidiary.
Texture Unit: Includes 4 texture address generators and 8 filtering units (supporting full-speed 2:1 anisotropic filtering). Unlike the scalar computations in the SM, the instruction source of the texture unit is the texture coordinates, and the output is interpolated texture values (the most common being RGBA), which are vectors. The acquired texture data will be stored in the Tex L1 cache, as data painstakingly brought in from the outside may be useful later.
SM (Streaming Multiprocessor): Finally, we come to the department responsible for computation at the lowest level.
I cache (Instruction cache): The tasks from the SMC to an SM (such as a fragment shader) cannot be completed immediately, and a large number of instructions need to be cached and executed in batches. C cache (Constant cache) and Shared Memory: We will further elaborate in the next chapter when we talk about general computing and various memory types. MT (multi-threaded) Issue: Yes, this is the manager of the SM department, responsible for breaking down Warp tasks into individual instructions for the worker bees to execute. It's the protagonist of this article, and its scheduling of Warps is key to the GPU's parallel capabilities. Although we haven't officially started to understand its working mechanism, we can already see that the so-called parallelism is not just a bunch of unorganized mobs gathering together to automatically achieve it. From top to bottom, inside and out, each layer has its managers, and the organizational structure is extremely strict and complex. SP (Streaming Processor): The main force for work, executing the most basic scalar floating-point operations, including add, multiply, multiply-add, and various integer operations. SFU (Special Function Unit): More complex operations, such as transcendental functions (exponential, logarithm, trigonometric functions, etc.), attribute interpolation (interpolating vertex attributes into each fragment input after rasterization), perspective correction (first interpolate divided by w attributes, then multiply back by w after interpolation).
Linear interpolation (left) and perspective-corrected interpolation (right) Grasshoppers on the same boat
After interviewing the workers, let's take a look at what they have to do. So, we need to start from the very beginning, the work they do may initially be a piece of shader code or a CUDA Kernel program, both are high-level languages, which will be compiled into intermediate instructions, then optimized by the optimizer into binary GPU instructions. If the intermediate instruction is a vector instruction (SIMD), it will also be converted into multiple Tesla SM scalar instructions, such as adding 4-dimensional vectors, which will be broken down into 4 scalar additions, because Nvidia has already eliminated the computing units for SIMD instructions in Tesla.
ISA (Instruction Set Architecture): So what instructions will be generated? Mainly there are three categories:
Computation: Floating-point integers, etc., addition and multiplication, min-max, comparison, type conversion,
Warp scheduling is the core of the entire GPU architecture. Different architectures may have variations in the names and numbers of components, and there might be splitting or merging of these components, but the characteristic of latency hiding remains unchanged throughout.